Data Extraction Tool
Extract Tables from PDFs with Precision
Transform messy PDF tables into clean, structured data in seconds. Built for researchers, students, and professionals.
Data Extraction Tool
Transform messy PDF tables into clean, structured data in seconds. Built for researchers, students, and professionals.
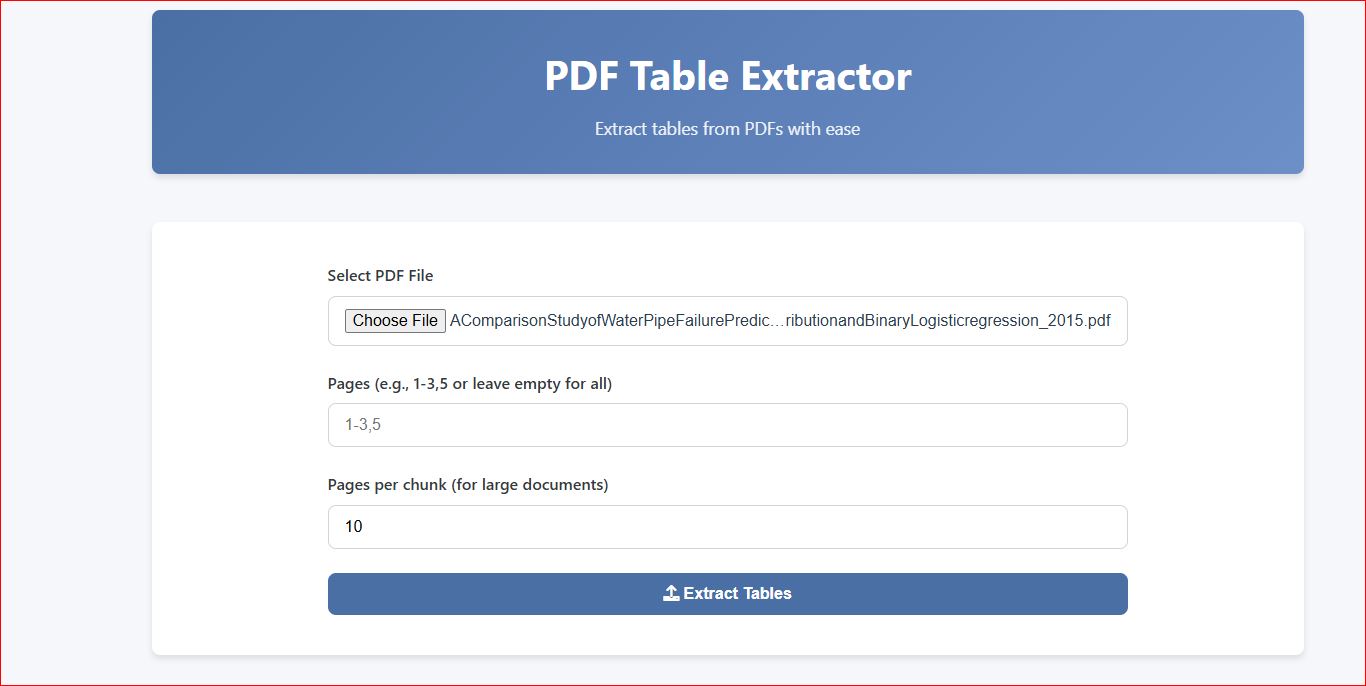
Extract structured table data from any PDF document.
Need more extractions? View plans →
Focused controls, cleaner exports, and enough guardrails for messy research and reporting workflows.
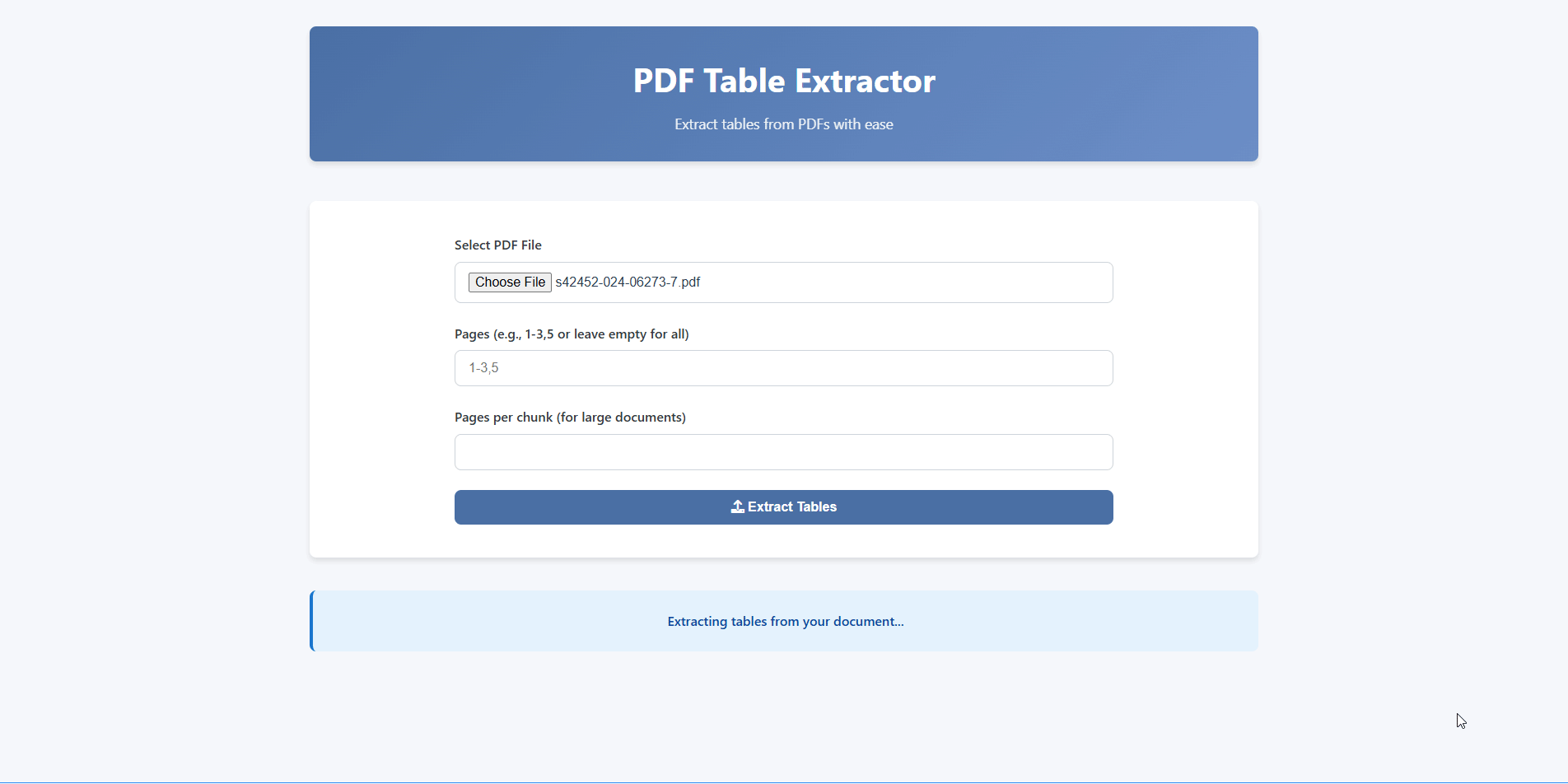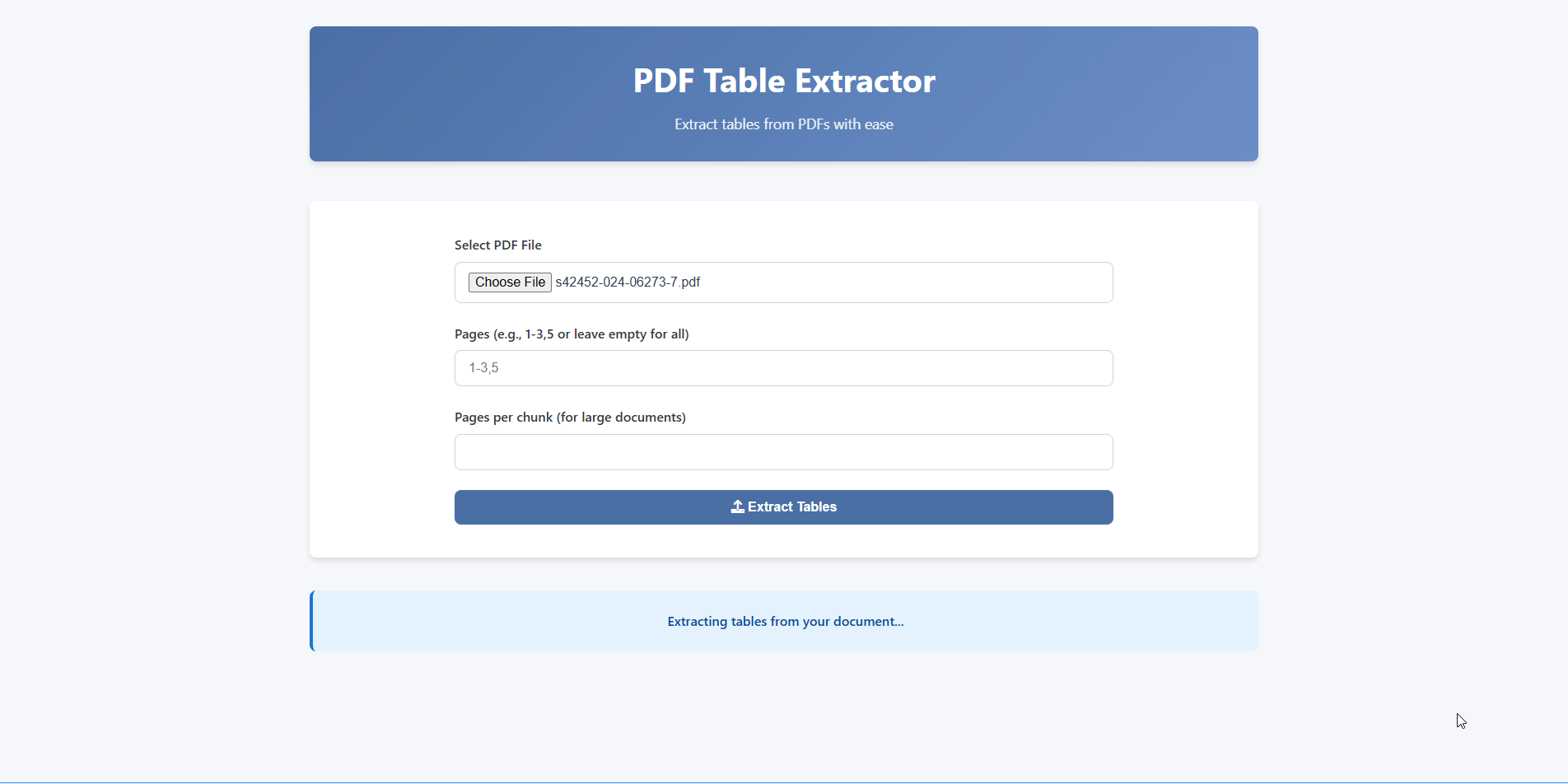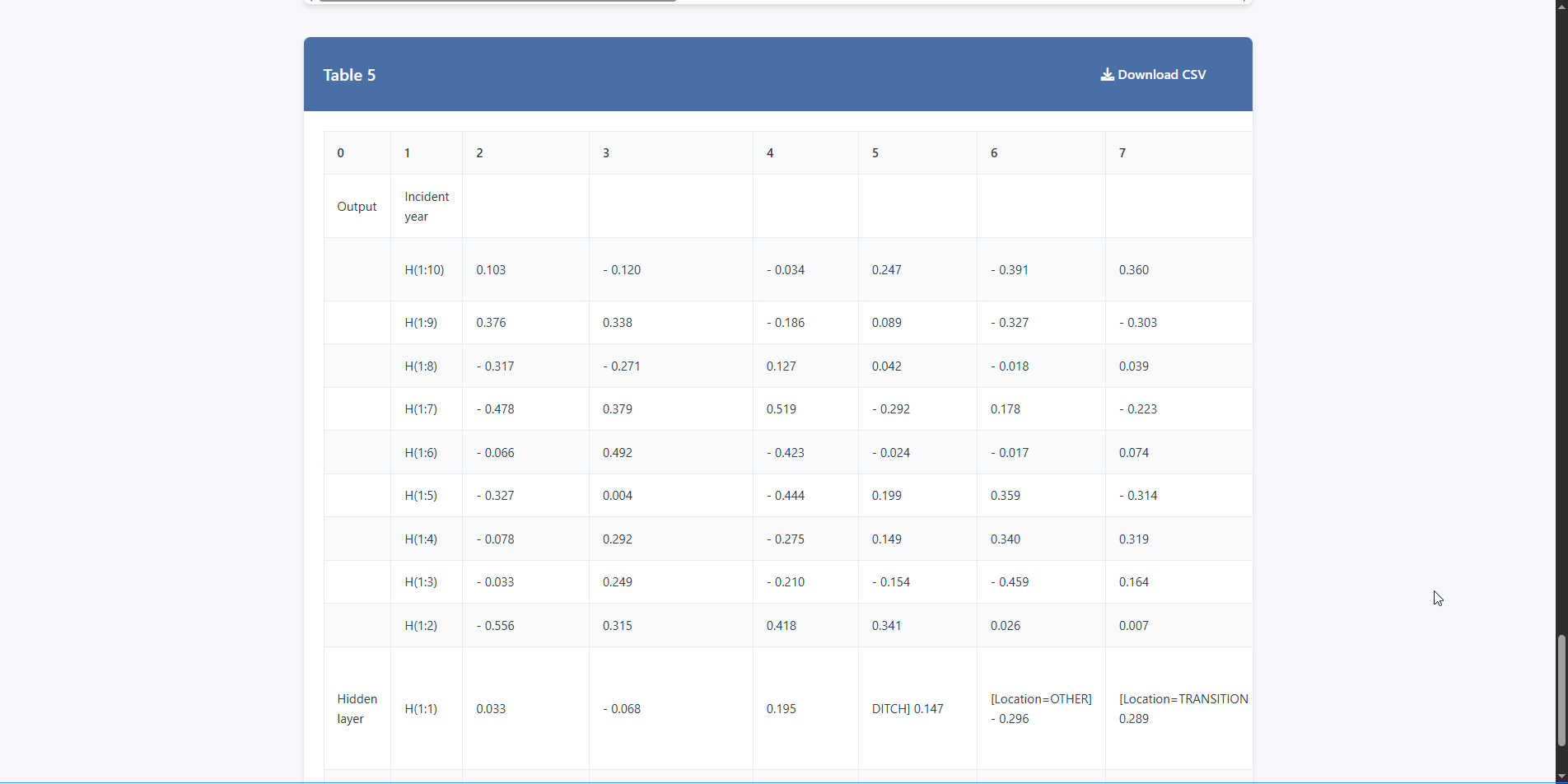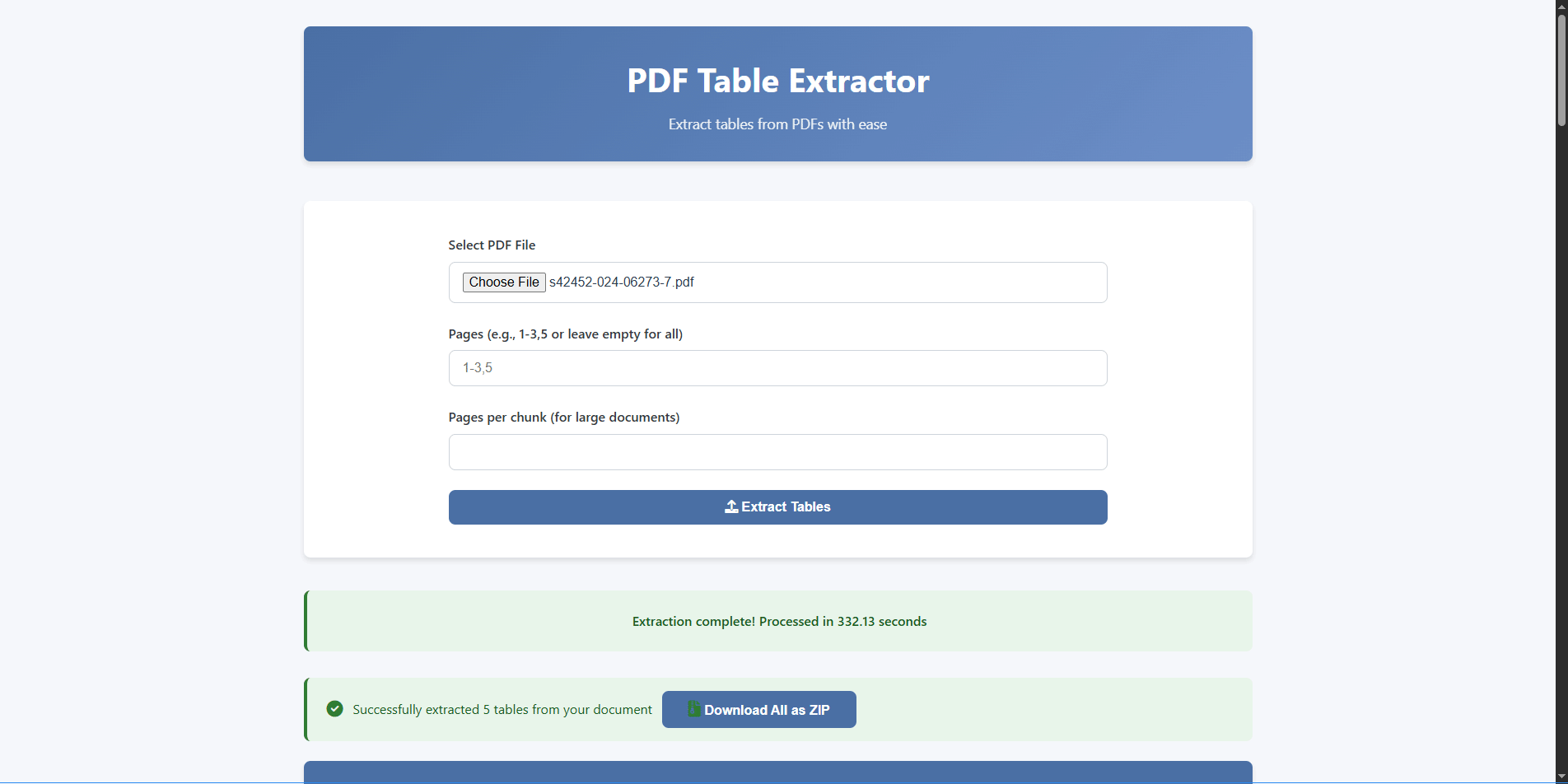
Accurately identifies and extracts even the most complex table structures — including merged cells and irregular layouts.
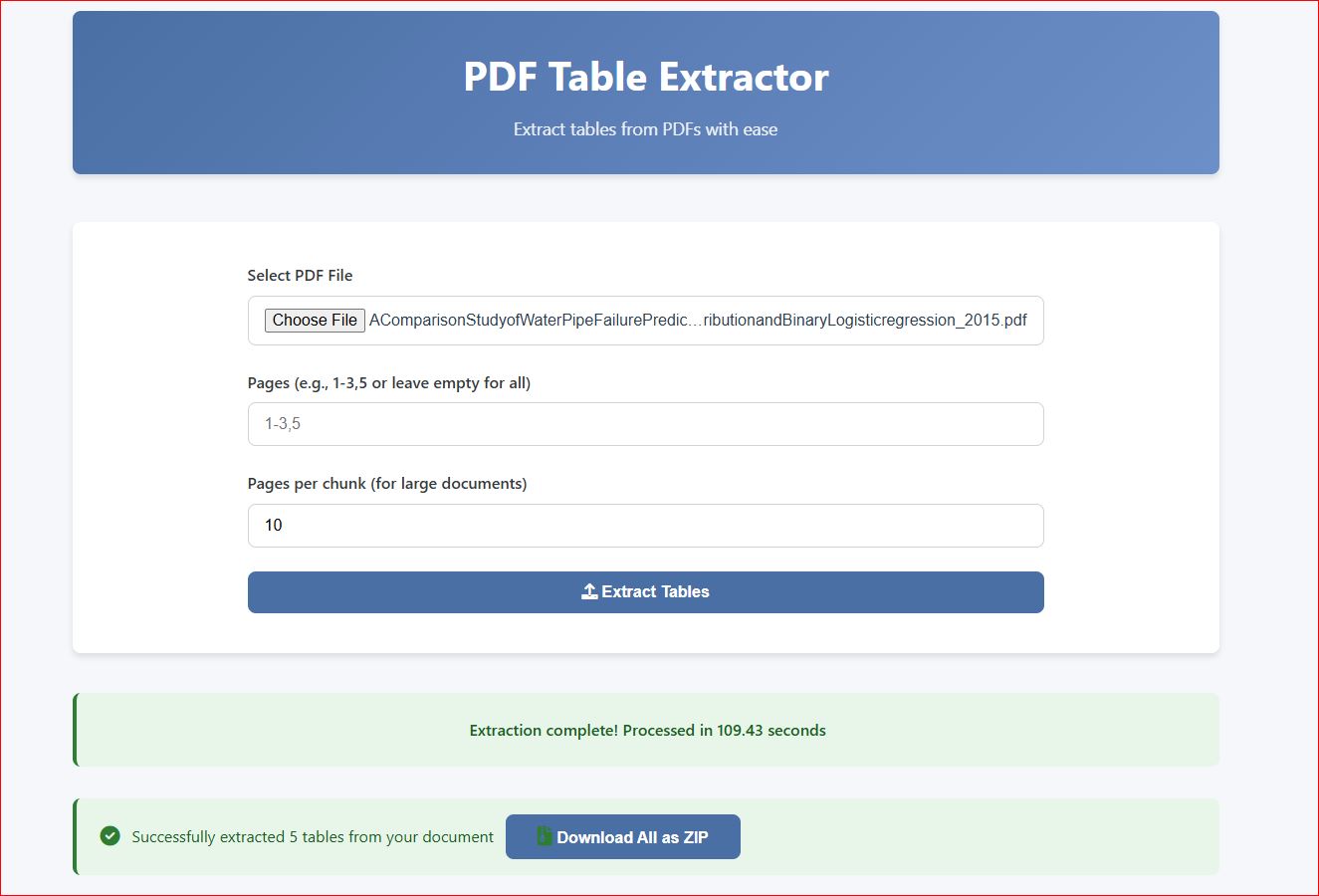
Process multiple pages or entire documents in one go with our efficient chunking system. Fast and reliable.
Export your extracted tables in CSV or Excel format for easy analysis in any tool — from Python to Google Sheets.
Three steps to clean, structured data
Drag and drop your PDF or click to browse. Supports any PDF with embedded or scanned tables.
Select specific pages or adjust chunk size. Defaults work well for most documents.
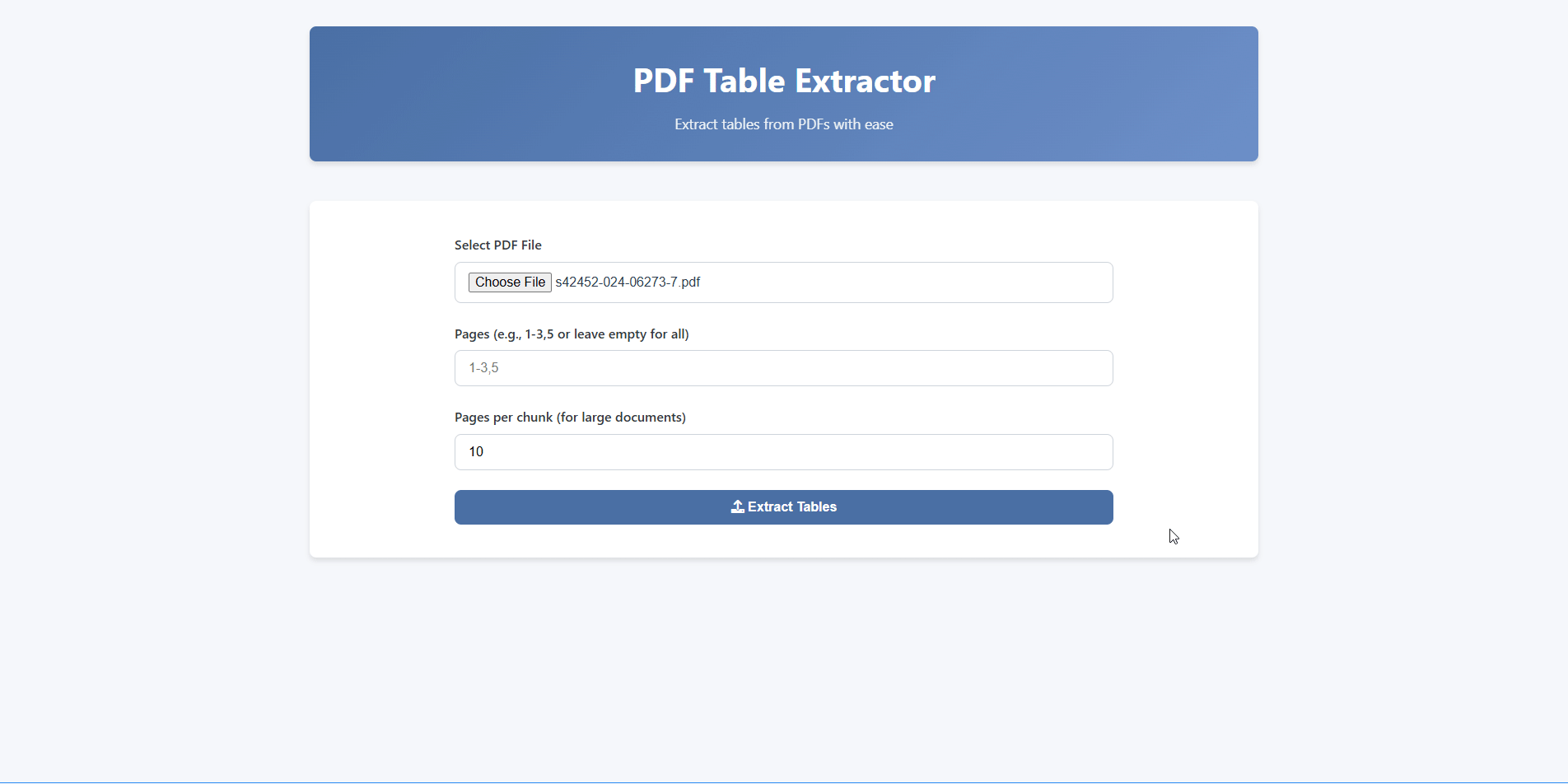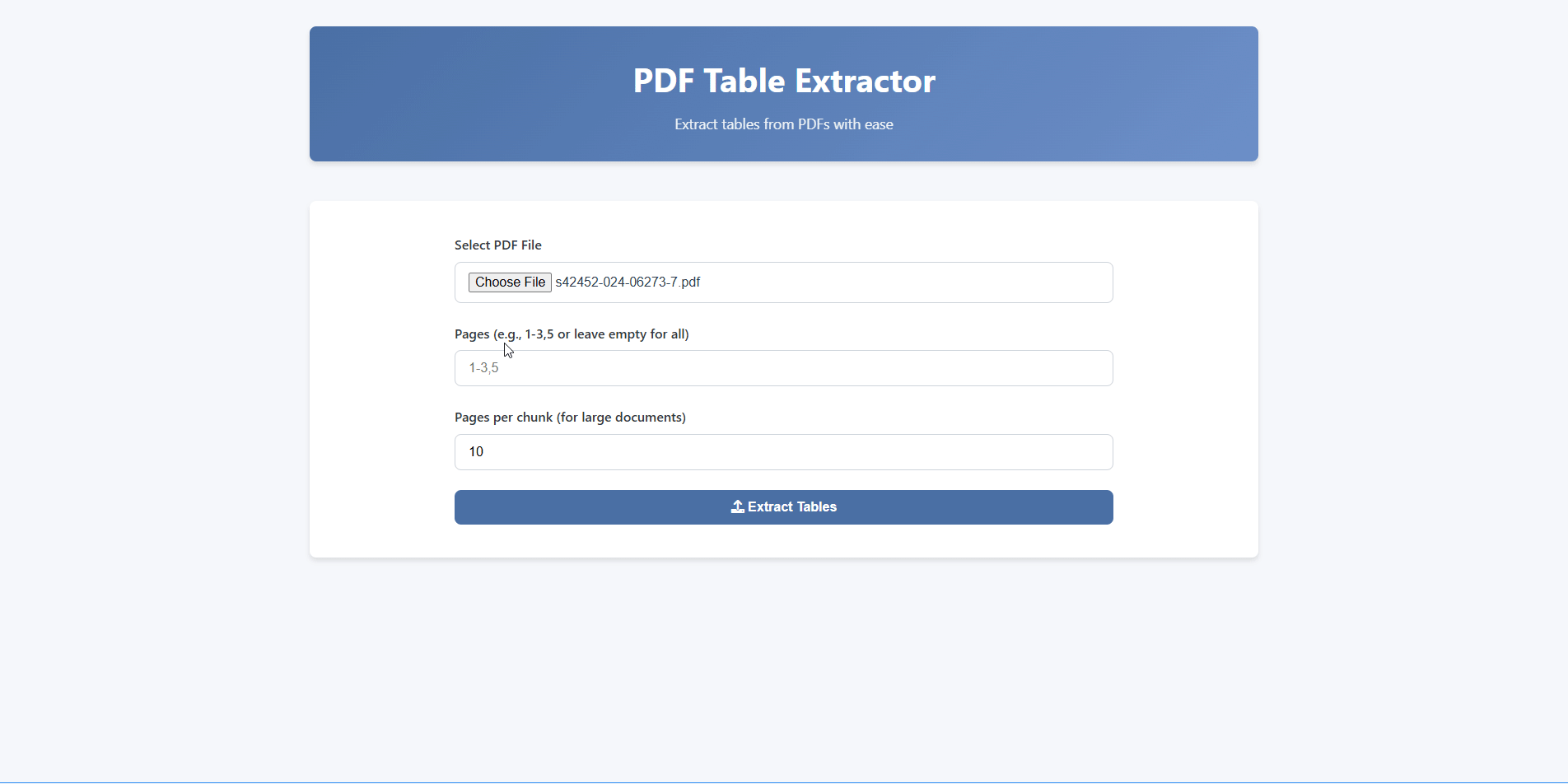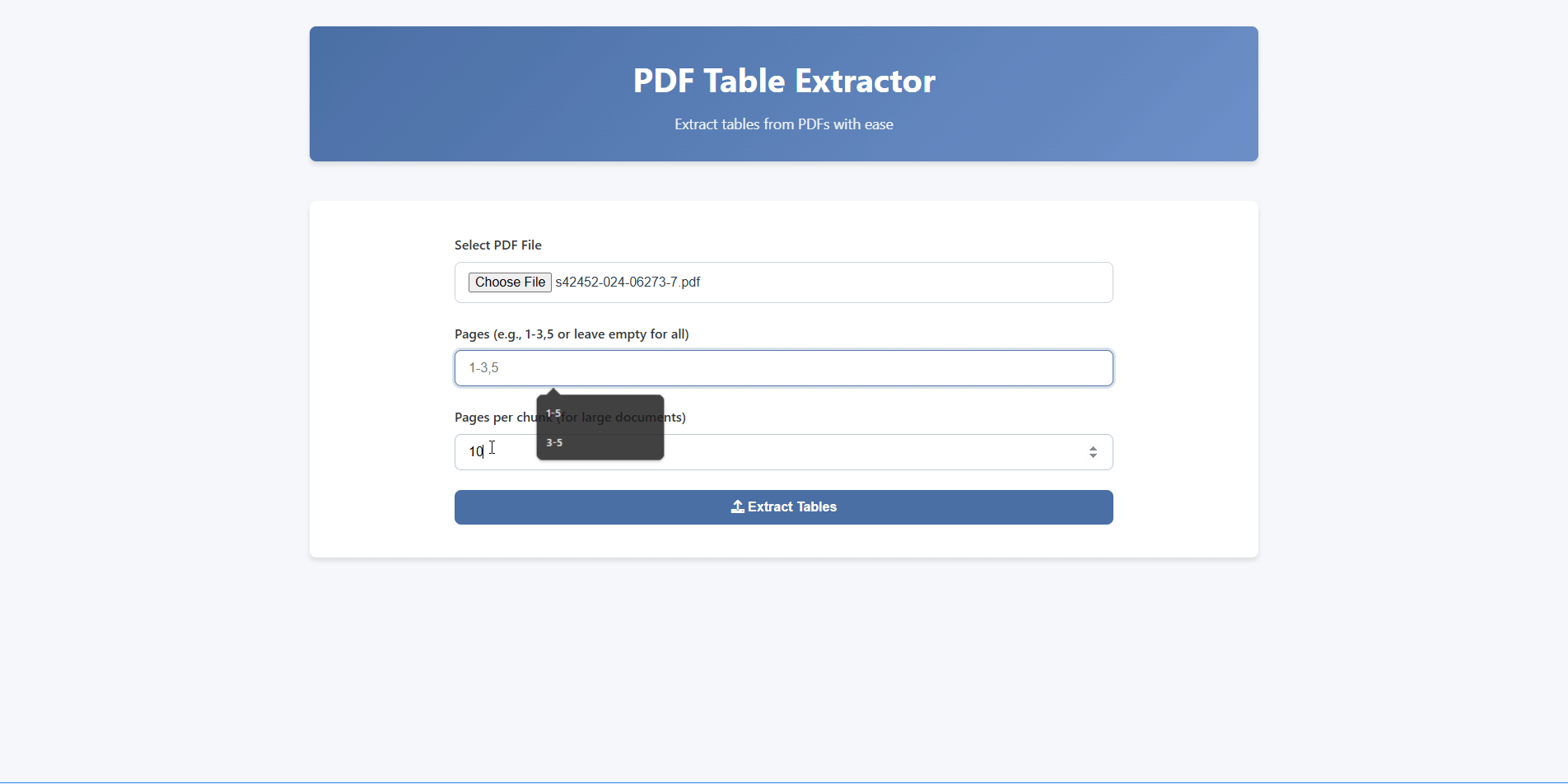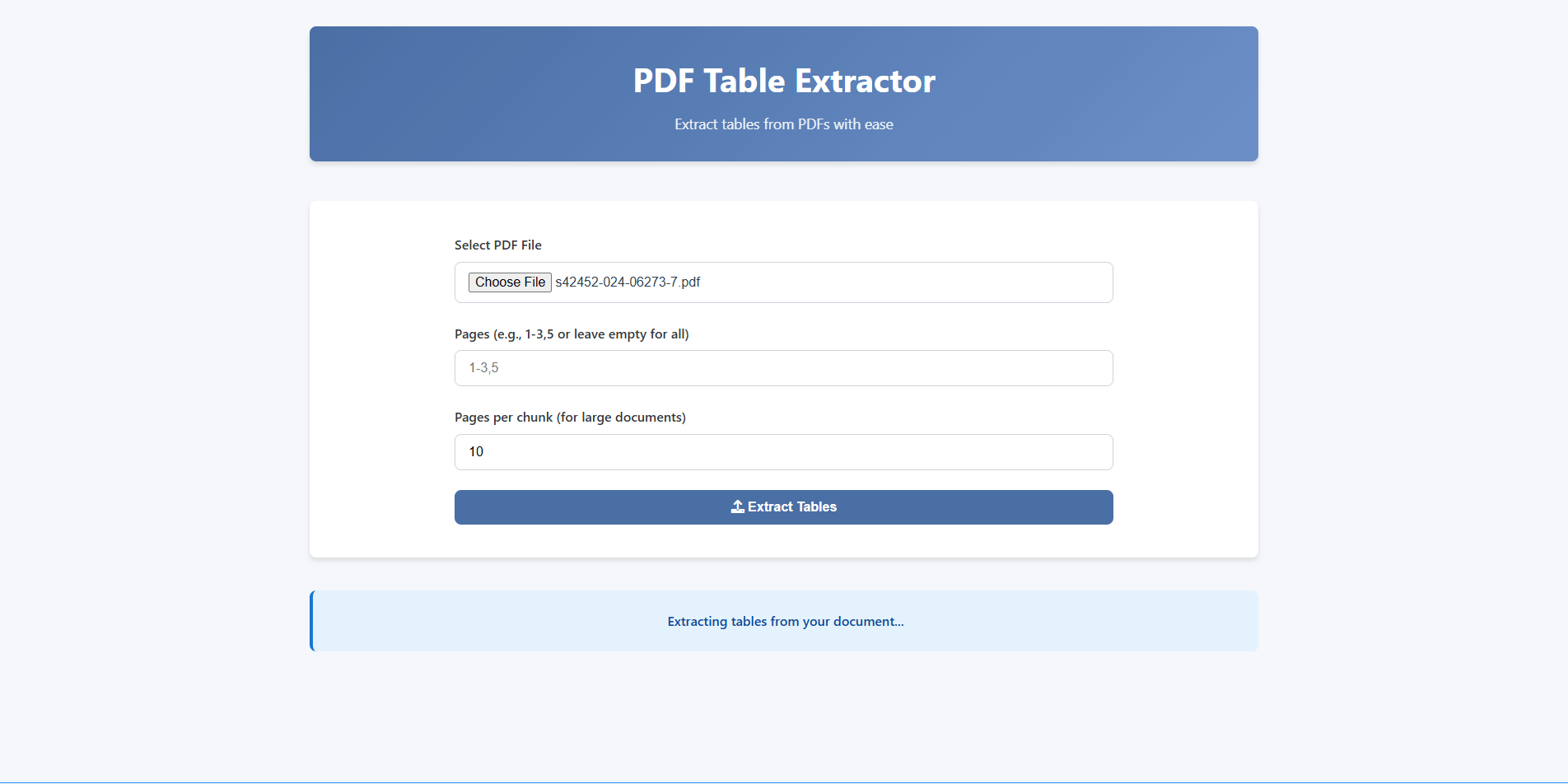
Receive your extracted tables in CSV, Excel, or JSON — ready for analysis.
Choose the plan that works for you.
One-Time Use
Single document processing
Monthly Subscription
Unlimited document processing
Cancel anytime
Need enterprise pricing? Contact us
Core Values
Designed to meet the needs of professionals working with complex PDFs — from academic researchers to financial analysts.
Built for Research & IndustryHandles multi-page, irregular tables, and scanned PDFs with high accuracy — optimized for batch processing and speed.
Precision at ScaleUsed across universities, enterprises, and data teams worldwide. Over 1.2 million tables extracted from thousands of documents.
Trusted GloballyBuilt for researchers, by researchers.
PDF2TABLE was created under the Data Bloom brand to solve a common challenge in data analysis: extracting tabular data from PDFs. Our mission is to make data extraction as simple and accurate as possible, saving you time and effort.
All purchases — including one-time credits and monthly subscriptions — are final and non-refundable. Because PDF2TABLE provides immediate, automated access to digital extraction services, we are unable to offer refunds once a payment has been processed.
If you experience a technical issue, our support team will work with you to resolve it promptly. Contact us at support@graduatego.com.
Join thousands of students, researchers, and professionals who trust PDF2TABLE.
Built for researchers, by researchers
PDF2TABLE was created under the Data Bloom brand to solve a common challenge in data analysis: extracting tabular data from PDFs. Our mission is to make data extraction as simple and accurate as possible, saving you time and effort in your research and analysis.
All purchases made on PDF2TABLE, including one-time credits and monthly subscriptions, are final and non-refundable. Because PDF2TABLE provides immediate, automated access to digital extraction services, we are unable to offer refunds once a payment has been processed.
If you experience a technical issue, our support team will work with you to resolve it promptly. For assistance, contact us at support@graduatego.com.
Join thousands of researchers, students and professionals who trust PDF2TABLE for their data extraction needs.
Try It Free View Pricing